

Autoscaling Horizontal avec HPA et KEDA
L'autoscaling horizontal permet d'ajuster automatiquement le nombre de réplicas d'un Deployment, StatefulSet ou ReplicaSet en fonction de métriques observées. Ce guide présente deux approches complémentaires : HPA (natif Kubernetes) et KEDA (événementiel avancé).
Introduction
L'HorizontalPodAutoscaler (HPA) est un contrôleur natif Kubernetes qui ajuste le nombre de Pods en fonction de métriques :
- Métriques CPU/Memory : via Metrics Server (intégré)
- Métriques custom : via Prometheus Adapter ou tout adaptateur compatible Metrics API
- Métriques externes : via External Metrics API
Approches de scaling : du plus simple au plus précis
Le scaling peut être mis en œuvre selon trois niveaux de complexité et de précision :
1. Scaling sur CPU/Memory (Premier niveau - Recommandé pour démarrer)- Simple : Metrics Server généralement préinstallé, configuration minimale
- Pas d'infrastructure supplémentaire : Fonctionne out-of-the-box
- Universel : Applicable à toutes les applications
- Imprécis : CPU/Memory ne reflètent pas toujours la charge réelle de l'application
- Réactif : Scale après saturation des ressources, pas de manière prédictive
- Précision : Basé sur des indicateurs métiers (requêtes/sec, latence, taux d'erreur, pool de connexions, etc.)
- Proactif : Scale avant saturation des ressources système
- Adapté au contexte : Reflète réellement la charge applicative
- Infrastructure requise : Nécessite Prometheus + Prometheus Adapter ou équivalent
- Configuration : Requiert instrumentation de l'application et configuration des règles
- Scale-to-zero : Économies maximales en l'absence de charge
- Sources multiples : 60+ scalers intégrés (files, bases, cloud services)
- Événementiel : Idéal pour traitement batch et workers
- Cold start : Latence au premier événement si scaled à zéro
KEDA (Kubernetes Event-Driven Autoscaling) étend le HPA standard en permettant le scaling basé sur des événements externes (files de messages, bases de données, métriques cloud, etc.) et supporte le scale-to-zero.
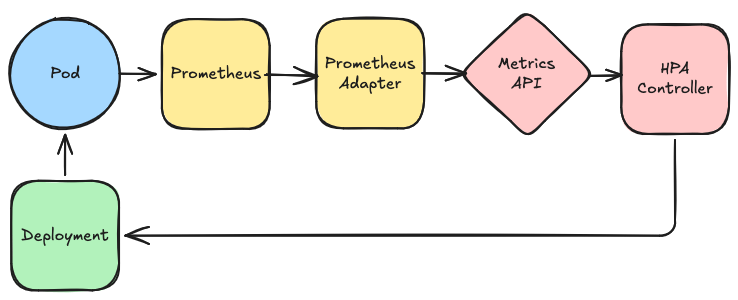
Architecture et composants
Stack HPA avec métriques personnalisées
| Composant | Rôle | Déploiement |
|---|---|---|
| Metrics Server | Métriques CPU/Memory des Pods | Généralement préinstallé sur le cluster |
| Prometheus | Collecte et stockage des métriques applicatives | Helm Chart prometheus-community/prometheus. Ce composant est préinstallé dans votre cluster SdV. |
| Prometheus Adapter | Exposition des métriques Prometheus dans l'API Kubernetes | Helm Chart prometheus-community/prometheus-adapter. Ce composant est préinstallé dans votre cluster SdV. |
| HPA Controller | Contrôleur natif Kubernetes | Intégré au Control Plane |
Flux de données
Prérequis
- Fichier
kubeconfigvalide avec les droits nécessaires (création deNamespace,Deployment,HPA) - Accès réseau pour la résolution DNS dynamique (pour l'exemple avec
nip.io) - Métriques CPU/Memory :
Metrics Serveropérationnel (vérifier aveckubectl top nodes)
Autoscaling basé sur CPU et Memory
Le cas d'usage le plus simple et le plus courant est le scaling basé sur les métriques CPU et Memory des Pods. Ces métriques sont fournies nativement par le Metrics Server.
Vérification de Metrics Server
Avant de créer un HPA, vérifiez que le Metrics Server fonctionne correctement :
# Vérifier que l'API metrics.k8s.io est disponible
kubectl get apiservices | grep metrics
# Tester la récupération des métriques des nodes
kubectl top nodes
# Tester la récupération des métriques des pods
kubectl top pods -ASi ces commandes échouent, le Metrics Server n'est pas installé ou non fonctionnel. Consultez la documentation SdV ou contactez l'équipe d'administration du cluster.
Exemple 1 : HPA basé sur CPU uniquement
Configuration minimale pour scaler un Deployment en fonction de l'utilisation CPU :
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-cpu-hpa
namespace: myapp
labels:
app: myapp
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70 # Scale up si CPU moyen > 70%Exemple 2 : HPA basé sur Memory uniquement
Configuration pour scaler en fonction de l'utilisation mémoire :
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-memory-hpa
namespace: myapp
labels:
app: myapp
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80 # Scale up si Memory moyenne > 80%Exemple 3 : HPA combinant CPU et Memory
Configuration recommandée combinant les deux métriques (le HPA scale si l'une des deux dépasse son seuil) :
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
namespace: myapp
labels:
app: myapp
monitoring: enabled
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 20
# Le HPA scale si CPU > 70% OU Memory > 80%
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
# Comportements de scaling pour éviter le flapping
behavior:
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 100 # Doubler le nombre de Pods maximum
periodSeconds: 60
selectPolicy: Max
scaleDown:
stabilizationWindowSeconds: 300 # 5 minutes
policies:
- type: Pods
value: 1
periodSeconds: 180 # Retirer 1 Pod toutes les 3 minutes
selectPolicy: MinExemple 4 : HPA avec valeurs absolues
Au lieu de pourcentages (Utilization), vous pouvez utiliser des valeurs absolues (AverageValue) :
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-absolute-hpa
namespace: myapp
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 10
metrics:
# Scale si CPU moyen > 500 millicores (0.5 core)
- type: Resource
resource:
name: cpu
target:
type: AverageValue
averageValue: 500m
# Scale si Memory moyenne > 1Gi
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageValue: 1GiDimensionnement des requests et limits
Pour que le HPA fonctionne correctement avec CPU/Memory, les requests et limits doivent être correctement dimensionnés dans votre Deployment :
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
namespace: myapp
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: app
image: myregistry/myapp:latest
ports:
- containerPort: 8080
resources:
requests:
cpu: 200m # CPU demandé au scheduler
memory: 256Mi # Memory demandée au scheduler
limits:
cpu: 1000m # CPU max (throttling au-delà)
memory: 512Mi # Memory max (OOMKill au-delà)Quality of Service (QoS) Classes
Kubernetes assigne automatiquement une QoS Class à chaque Pod selon la configuration requests et limits. Cette classe détermine la priorité d'éviction en cas de pression sur les ressources du nœud.
| QoS Class | Configuration | Priorité éviction | Cas d'usage typique |
|---|---|---|---|
| Guaranteed | limits = requests pour CPU ET Memory | 🛡️ Haute (évincé en dernier) | Bases de données, services critiques |
| Burstable | requests < limits OU seulement requests | ⚠️ Moyenne (évincé en second) | Applications web/API, charge variable |
| BestEffort | Ni requests ni limits | ❌ Basse (évincé en premier) | Dev/test uniquement |
Guaranteed :
- ✅ Ressources garanties et réservées
- ✅ Prévisibilité maximale
- ✅ Priorité d'exécution maximale
- ❌ Pas de burst possible
- ❌ Peut gaspiller des ressources inutilisées
Burstable :
- ✅ Burst autorisé lors des pics
- ✅ Optimisation de l'utilisation des ressources
- ✅ Flexible et économique
- ❌ Peut être évincé en cas de pression
- ❌ Moins prévisible
BestEffort :
- ✅ Utilise toutes les ressources disponibles
- ✅ Pas de contrainte
- ❌ Aucune garantie de ressources
- ❌ Évincé en premier en cas de pression
- ❌ À éviter en production
# Guaranteed - Workload critique
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 500m # = requests
memory: 512Mi # = requests
# Burstable - Workload standard (recommandé pour la plupart des cas)
resources:
requests:
cpu: 200m
memory: 256Mi
limits:
cpu: 1000m # 5x requests (burst possible)
memory: 512Mi # 2x requests
# BestEffort - À éviter en production
resources: {} # Aucune limiteCalibration des requests avec des métriques réelles
Processus recommandé pour calibrer les requests :
# 1. Déployer l'application avec des requests initiaux (estimation)
kubectl apply -f deployment.yaml
# 2. Observer la consommation réelle sous charge normale
kubectl top pods -n myapp --containers
# Exemple de sortie :
# POD NAME CPU(cores) MEMORY(bytes)
# myapp-abc123 app 150m 180Mi
# myapp-def456 app 170m 200Mi
# 3. Calculer la moyenne et ajouter une marge de 20-30%
# Moyenne CPU : 160m -> requests: 200m (160m * 1.25)
# Moyenne Memory : 190Mi -> requests: 250Mi (190Mi * 1.3)
# 4a. Définir les limits pour une QoS Burstable (recommandé pour la plupart des cas)
# Permet le burst lors des pics de charge
# CPU limits: 1000m (5x requests pour gérer les pics)
# Memory limits: 500Mi (2x requests)
# 4b. Ou définir les limits pour une QoS Guaranteed (workloads critiques)
# Ressources garanties, priorité d'éviction maximale
# CPU limits: 200m (= requests)
# Memory limits: 250Mi (= requests)
# 5. Mettre à jour le Deployment avec les valeurs calibrées (exemple Burstable)
kubectl set resources deployment myapp -n myapp \
--requests=cpu=200m,memory=250Mi \
--limits=cpu=1000m,memory=500Mi
# 6. Tester le scaling sous charge (load test)
# Utiliser des outils comme k6, Apache Bench, Gatling, etc.Tester le HPA
Une fois le HPA créé, testez son fonctionnement :
# Créer le HPA
kubectl apply -f hpa-cpu-memory.yaml
# Observer l'état initial
kubectl get hpa -n myapp
# Générer de la charge CPU (test simple)
kubectl run load-generator --image=busybox --restart=Never -n myapp -- /bin/sh -c "while true; do wget -q -O- http://myapp-service:8080; done"
# Observer le scaling en temps réel
kubectl get hpa -n myapp -w
# Consulter les événements de scaling
kubectl describe hpa myapp-hpa -n myapp
# Supprimer le générateur de charge
kubectl delete pod load-generator -n myapp
# Observer le scale down (après stabilizationWindowSeconds)
kubectl get hpa -n myapp -wCommandes de diagnostic
# Vérifier que le HPA récupère correctement les métriques
kubectl get hpa myapp-hpa -n myapp -o yaml
# Afficher les métriques actuelles via l'API
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/myapp/pods" | jq .
# Consulter les logs du Metrics Server (si problème)
kubectl logs -n kube-system -l k8s-app=metrics-server
# Vérifier les événements du HPA
kubectl get events -n myapp --sort-by='.lastTimestamp' | grep HorizontalPodAutoscalerTableau récapitulatif : Recommandations de seuils
| Métrique | Seuil HPA recommandé | requests conseillés |
|---|---|---|
| CPU | 70-80% | Consommation moyenne + 20% |
| Memory | 75-85% | Consommation moyenne + 30% |
| CPU + Memory | CPU: 70%, Memory: 80% | Calibrés séparément |
limits selon la QoS Class :
| QoS Class | CPU limits | Memory limits | Quand utiliser |
|---|---|---|---|
| Burstable | 2x à 5x requests | 1.5x à 2x requests | Applications web/API (défaut recommandé) |
| Guaranteed | = requests | = requests | Workloads critiques uniquement |
Cas d'usage : Autoscaling PHP-FPM (métriques custom)
Dans cet exemple, nous allons scaler un applicatif PHP basé sur le taux d'utilisation des workers php-fpm. L'approche est transposable à d'autres applicatifs exposant des métriques custom (pools de connexions, files d'attente, latences, etc.).
Objectif
- Collecter les métriques
phpfpm_active_processesetphpfpm_total_processes - Calculer un ratio d'utilisation :
phpfpm_process_utilization_rate - Scaler automatiquement lorsque ce ratio dépasse 50%
Prérequis pour métriques custom
Le cluster SdV dispose déjà de l'infrastructure nécessaire pour les métriques custom :
- Prometheus : Préinstallé pour la collecte et le stockage des métriques
- Prometheus Adapter : Préinstallé pour exposer les métriques dans l'API
custom.metrics.k8s.io - Prometheus Operator : Préinstallé pour gérer la configuration de scraping via des CRD (ServiceMonitor, PodMonitor)
Méthodes de collecte de métriques
Il existe trois approches pour faire collecter vos métriques applicatives par Prometheus. Choisissez celle qui correspond le mieux à votre cas d'usage.
1. Annotations Prometheus (Approche simple)
Principe : Prometheus découvre automatiquement les Pods via leurs annotations. Cette méthode fonctionne si Prometheus est configuré avec Service Discovery Kubernetes.
metadata:
annotations:
prometheus.io/scrape: "true" # Active le scraping
prometheus.io/port: "9253" # Port d'exposition des métriques
prometheus.io/path: "/metrics" # Path de l'endpoint (défaut: /metrics)- ✅ Simple et rapide à mettre en place
- ✅ Pas de ressource supplémentaire à créer
- ✅ Fonctionne out-of-the-box si Prometheus est configuré pour
- ❌ Moins déclaratif (configuration mélangée aux annotations)
- ❌ Difficile à gérer à grande échelle
- ❌ Dépend de la configuration Prometheus (peut ne pas fonctionner)
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
namespace: myapp
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9253"
prometheus.io/path: "/metrics"
spec:
containers:
- name: app
image: myapp:latest
ports:
- containerPort: 8080
name: http
- containerPort: 9253
name: metrics2. ServiceMonitor (Approche recommandée)
Principe : Avec Prometheus Operator, vous créez un objet ServiceMonitor qui décrit comment scraper un Service Kubernetes. C'est l'approche déclarative et la plus maintainable.
- Un
Servicequi expose vos Pods - Un
ServiceMonitorqui référence ce Service
- ✅ Déclaratif et Infrastructure as Code
- ✅ Géré par Prometheus Operator (auto-reloading)
- ✅ Facile à gérer à grande échelle
- ✅ Support avancé (authentification, TLS, relabeling)
- ✅ Isolé de la configuration Prometheus
- ❌ Ressource supplémentaire à maintenir (
Service+ServiceMonitor)
# Service exposant les métriques
apiVersion: v1
kind: Service
metadata:
name: myapp-metrics
namespace: myapp
labels:
app: myapp
metrics: enabled # Label important pour le ServiceMonitor
spec:
selector:
app: myapp
ports:
- name: metrics # Le nom du port est important
port: 9253
targetPort: 9253ServiceMonitor :
# Lister les ServiceMonitors
kubectl get servicemonitor -n myapp
# Détails d'un ServiceMonitor
kubectl describe servicemonitor myapp-monitor -n myapp
# Vérifier que Prometheus a chargé le ServiceMonitor
# (accéder à Prometheus UI et aller dans Status > Targets)3. PodMonitor (Alternative aux ServiceMonitor)
Principe : Similaire au ServiceMonitor, mais scrape directement les Pods sans passer par un Service. Utile pour les Pods sans Service ou avec plusieurs ports de métriques.
- Scraping direct des
Pods(pas deServicerequis) - Utile pour les
DaemonSets,StatefulSets - Peut scraper plusieurs ports par Pod
- Moins stable que
ServiceMonitor(Podséphémères) - Pas de load balancing
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: myapp-pod-monitor
namespace: myapp
labels:
app: myapp
release: sdv-monitoring
spec:
# Sélecteur des Pods à surveiller
selector:
matchLabels:
app: myapp
# Namespace(s) à surveiller
namespaceSelector:
matchNames:
- myapp
# Configuration du scraping
podMetricsEndpoints:
- port: metrics # Nom du port défini dans le Pod
interval: 30s
path: /metrics
scheme: http
# Relabeling optionnel
relabelings:
- sourceLabels: [__meta_kubernetes_pod_name]
targetLabel: instanceTableau comparatif des méthodes
| Critère | Annotations | ServiceMonitor | PodMonitor |
|---|---|---|---|
| Simplicité | ⭐⭐⭐ Très simple | ⭐⭐ Moyen | ⭐⭐ Moyen |
| Déclaratif | ❌ Non | ✅ Oui | ✅ Oui |
| Prérequis | Service Discovery activé | Aucun (préinstallé) | Aucun (préinstallé) |
| Scalabilité | ⭐ Limitée | ⭐⭐⭐ Excellente | ⭐⭐ Bonne |
| Maintenance | ⭐ Difficile | ⭐⭐⭐ Facile | ⭐⭐ Moyenne |
| Fonctionnalités avancées | ❌ Limitées | ✅ Complètes | ✅ Complètes |
| Service requis | ❌ Non | ✅ Oui | ❌ Non |
| Cas d'usage | Prototypage, dev | Production (recommandé) | DaemonSets, StatefulSets |
Recommandations
Vérification de l'API custom metrics
Vérifiez que l'API custom.metrics.k8s.io est disponible :
# Vérifier l'API custom metrics
kubectl get apiservices | grep custom.metrics
# Lister les métriques custom disponibles (exemple)
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .Configuration de l'applicatif
Exposition des métriques PHP-FPM
Les images officielles PHP-FPM n'exposent pas nativement de métriques Prometheus. Nous allons déployer un sidecar container (php-fpm_exporter) qui scrape le endpoint /fpm-status et expose les métriques au format Prometheus.
Deployment avec sidecar exporter :
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-php
namespace: myapp
labels:
app: myapp
tier: backend
spec:
replicas: 2
selector:
matchLabels:
app: myapp
tier: backend
template:
metadata:
labels:
app: myapp
tier: backend
annotations:
# Annotations pour Prometheus Service Discovery
prometheus.io/scrape: "true"
prometheus.io/port: "9253"
prometheus.io/path: "/metrics"
spec:
containers:
# Conteneur applicatif principal (PHP-FPM)
- name: php-fpm
image: php:8.2-fpm-alpine
ports:
- containerPort: 9000
name: fastcgi
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
# ... autres configurations (volumes, env, etc.)
# Sidecar pour exposer les métriques PHP-FPM
- name: fpm-metrics
image: hipages/php-fpm_exporter:latest
ports:
- containerPort: 9253
name: metrics
env:
# Adresse FastCGI du pool PHP-FPM (local via 127.0.0.1)
- name: PHP_FPM_SCRAPE_URI
value: tcp://127.0.0.1:9000/fpm-status
# Port d'écoute de l'exporter
- name: PHP_FPM_WEB_LISTEN_ADDRESS
value: :9253
# Path des métriques
- name: PHP_FPM_WEB_TELEMETRY_PATH
value: /metrics
# Correction des compteurs de process (recommandé)
- name: PHP_FPM_FIX_PROCESS_COUNT
value: "true"
# Niveau de log
- name: PHP_FPM_LOG_LEVEL
value: info
# Health checks
readinessProbe:
httpGet:
path: /metrics
port: 9253
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /metrics
port: 9253
initialDelaySeconds: 10
periodSeconds: 10
startupProbe:
httpGet:
path: /metrics
port: 9253
failureThreshold: 30
periodSeconds: 2
resources:
requests:
cpu: 20m
memory: 32Mi
limits:
cpu: 50m
memory: 64MiConfiguration de la collecte Prometheus
Vous avez deux options pour faire collecter vos métriques par Prometheus :
Option 1 : Annotations (déjà configurées)
Les annotations ajoutées dans le Deployment ci-dessus suffisent si Prometheus est configuré avec Service Discovery :
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9253"
prometheus.io/path: "/metrics"Option 2 : ServiceMonitor (recommandé)
Créez un Service et un ServiceMonitor pour une approche déclarative :
# Service pour exposer les métriques PHP-FPM
apiVersion: v1
kind: Service
metadata:
name: myapp-php-metrics
namespace: myapp
labels:
app: myapp
tier: backend
metrics: phpfpm
spec:
selector:
app: myapp
tier: backend
ports:
- name: metrics
port: 9253
targetPort: 9253
protocol: TCPDéployez les ressources :
# Déployer l'application
kubectl apply -f deployment.yaml
# Déployer le ServiceMonitor (recommandé sur cluster SdV)
kubectl apply -f servicemonitor-phpfpm.yaml
# Vérifier le ServiceMonitor
kubectl get servicemonitor -n myapp
kubectl describe servicemonitor myapp-php-metrics -n myappVérification de la collecte
Vérifiez que Prometheus scrape correctement les métriques :
# Accéder à l'interface Prometheus et exécuter cette requête PromQL
phpfpm_active_processes
# Ou via port-forward (adapter le namespace et le service selon votre cluster)
kubectl port-forward -n <namespace-prometheus> svc/<nom-service-prometheus> 9090:80
# Puis ouvrir http://localhost:9090Configuration du HPA
Création du HPA avec métrique custom
L'objet HPA doit être déployé dans le même Namespace que l'application à scaler. Il surveille périodiquement la métrique et ajuste le nombre de réplicas selon les seuils définis.
phpfpm_process_utilization_rate :
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-php-hpa
namespace: myapp
labels:
app: myapp
spec:
# Cible du scaling
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-php
# Limites de scaling
minReplicas: 2
maxReplicas: 10
# Métriques de scaling
metrics:
- type: Pods
pods:
metric:
name: phpfpm_process_utilization_rate
target:
type: AverageValue
averageValue: "50" # Scale up si le ratio dépasse 50%
# Comportements de scaling (optionnel mais recommandé)
behavior:
scaleUp:
stabilizationWindowSeconds: 60 # Attendre 60s avant un scale up
policies:
- type: Pods
value: 2 # Ajouter max 2 pods
periodSeconds: 60 # Par période de 60s
- type: Percent
value: 50 # Ou augmenter de 50%
periodSeconds: 60
selectPolicy: Max # Choisir la politique la plus agressive
scaleDown:
stabilizationWindowSeconds: 300 # Attendre 5min avant un scale down
policies:
- type: Pods
value: 1 # Retirer max 1 pod
periodSeconds: 120 # Par période de 2min
selectPolicy: Min # Choisir la politique la plus conservatriceAppliquez le HPA :
kubectl apply -f hpa.yamlVérification et monitoring du HPA
# Vérifier l'état du HPA
kubectl get hpa -n myapp
# Affichage détaillé avec métriques actuelles
kubectl describe hpa myapp-php-hpa -n myapp
# Surveiller en temps réel
kubectl get hpa -n myapp -w
# Consulter les événements de scaling
kubectl get events -n myapp --sort-by='.lastTimestamp' | grep HPASortie exemple :
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-php-hpa Deployment/myapp-php 42/50 2 10 2 5mCommandes kubectl utiles
# Lister tous les HPA du cluster
kubectl get hpa --all-namespaces
# Tester le scaling manuellement (pour debug)
kubectl scale deployment myapp-php --replicas=5 -n myapp
# Supprimer temporairement le HPA (revenir au scaling manuel)
kubectl delete hpa myapp-php-hpa -n myapp
# Consulter les métriques via l'API custom.metrics
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/myapp/pods/*/phpfpm_process_utilization_rate" | jq .
# Diagnostiquer les erreurs de récupération de métriques (adapter le namespace Prometheus)
kubectl logs -n <namespace-prometheus> -l app.kubernetes.io/name=prometheus-adapter
# Vérifier que Metrics Server fonctionne (pour CPU/Memory)
kubectl top nodes
kubectl top pods -n myappBonnes pratiques HPA
Dimensionnement des seuils
| Métrique | Seuil recommandé | Justification |
|---|---|---|
| CPU | 70-80% | Laisse une marge pour les pics temporaires |
| Memory | 80-85% | Évite les OOMKill tout en optimisant l'utilisation |
| Métriques custom | Variable | Dépend de la nature de la métrique (pools, queues, latences...) |
Éviter le flapping
Le flapping (oscillation rapide du nombre de Pods) peut survenir si :
- Les seuils sont trop proches de la charge moyenne
- La fenêtre de stabilisation (
stabilizationWindowSeconds) est trop courte - Les métriques sont bruitées (pics aléatoires)
- Augmenter
stabilizationWindowSeconds(5-10 minutes pour scale down) - Utiliser des métriques lissées (moyenne sur 5-10min)
- Définir des politiques
scaleDownprudentes (1 Pod toutes les 2-5 minutes)
Sizing initial
Avant d'activer l'autoscaling :
- Load test votre application pour connaître les seuils réalistes
- Définissez
minReplicasen fonction de la charge de base - Calibrez les
requestsCPU/Memory pour que les métriques soient représentatives
Monitoring et alerting
Mettez en place des alertes sur :
- HPA atteignant
maxReplicas(capacité saturée) - HPA ne pouvant pas récupérer les métriques (erreur adaptateur)
- Scaling trop fréquent (flapping détecté)
- Temps de réponse ou erreurs applicatives pendant le scaling
Autoscaling événementiel avec KEDA
KEDA (Kubernetes Event-Driven Autoscaling) est un projet CNCF qui étend les capacités de l'HPA standard pour supporter :
- Le scale-to-zero (réduire à 0 réplica en l'absence de charge)
- Plus de 60 scalers prêts à l'emploi (RabbitMQ, Kafka, Azure Queue, AWS SQS, Redis, PostgreSQL, etc.)
- Des sources de métriques externes sans adapter personnalisé
- L'agrégation de plusieurs métriques avec des stratégies complexes
Différences HPA vs KEDA
| Critère | HPA standard | KEDA |
|---|---|---|
| Scale-to-zero | Non (minReplicas ≥ 1) | Oui (0 réplica possible) |
| Sources de métriques | CPU, Memory, Custom, External | 60+ scalers intégrés |
| Configuration | Objet HPA natif | Objet ScaledObject (CRD) |
| Complexité | Nécessite adaptateurs pour métriques custom | Scalers clé en main |
| Cas d'usage | Applications web, API REST | Traitement asynchrone, batch, workers |
Installation de KEDA
KEDA se déploie via Helm dans un namespace dédié :
# Ajouter le repo Helm KEDA
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
# Installer KEDA
kubectl create namespace keda
helm install keda kedacore/keda --namespace kedaVérifiez l'installation :
kubectl get pods -n keda
kubectl api-resources | grep kedaVous devriez voir les CRD suivantes :
ScaledObject: Pour scaler desDeployments/StatefulSetsScaledJob: Pour créer desJobsà la demandeTriggerAuthentication: Pour gérer les authentifications externes
Exemple 1 : Scaling basé sur RabbitMQ
Cas d'usage : Une application consomme des messages d'une queue RabbitMQ. On souhaite scaler en fonction de la profondeur de la queue.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-consumer-scaler
namespace: myapp
spec:
# Cible du scaling
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: message-consumer
# Scale-to-zero activé
minReplicaCount: 0
maxReplicaCount: 30
# Période d'inactivité avant scale-to-zero
cooldownPeriod: 300 # 5 minutes
# Période de polling des métriques
pollingInterval: 30 # 30 secondes
# Scalers (sources de métriques)
triggers:
- type: rabbitmq
metadata:
# Connection string (ou via TriggerAuthentication)
host: amqp://user:password@rabbitmq.myapp.svc.cluster.local:5672/vhost
queueName: tasks
queueLength: "5" # Scale up si plus de 5 messages par Pod
protocol: autoTriggerAuthentication (recommandé) :
apiVersion: v1
kind: Secret
metadata:
name: rabbitmq-secret
namespace: myapp
type: Opaque
stringData:
host: amqp://user:password@rabbitmq.myapp.svc.cluster.local:5672/vhostExemple 2 : Scaling basé sur Prometheus
KEDA peut aussi consommer des métriques Prometheus (alternative à Prometheus Adapter) :
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaler
namespace: myapp
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
# Adapter l'URL selon votre cluster SdV
serverAddress: http://<prometheus-service>.<namespace>.svc.cluster.local:80
# Requête PromQL
query: sum(rate(http_requests_total{job="myapp"}[2m]))
# Seuil : 1 réplica pour 100 requêtes/sec
threshold: "100"Exemple 3 : Scaling basé sur un Cron
Scaling préventif basé sur un calendrier (montée en charge anticipée) :
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaler
namespace: myapp
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicaCount: 1
maxReplicaCount: 20
triggers:
# Scale up à 10 réplicas entre 8h et 18h en semaine
- type: cron
metadata:
timezone: Europe/Paris
start: 0 8 * * 1-5 # Lundi-Vendredi à 8h
end: 0 18 * * 1-5 # Lundi-Vendredi à 18h
desiredReplicas: "10"Exemple 4 : ScaledJob pour traitement batch
Créer des Jobs Kubernetes à la demande (au lieu de scaler un Deployment) :
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: batch-processor
namespace: myapp
spec:
jobTargetRef:
template:
metadata:
labels:
app: batch-job
spec:
containers:
- name: processor
image: myregistry/batch-processor:latest
env:
- name: TASK_ID
value: "{{ .Task }}"
restartPolicy: Never
# Nombre max de jobs simultanés
maxReplicaCount: 50
# Stratégie de rollout (default, gradual, accurate)
rollout:
strategy: default
propagationPolicy: foreground
triggers:
- type: rabbitmq
metadata:
queueName: batch-tasks
queueLength: "10" # 1 Job pour 10 messagesCommandes kubectl pour KEDA
# Lister les ScaledObjects
kubectl get scaledobject -A
kubectl get so -A # Alias court
# Détails d'un ScaledObject
kubectl describe scaledobject rabbitmq-consumer-scaler -n myapp
# Lister les HPA créés automatiquement par KEDA
kubectl get hpa -n myapp
# Consulter les logs KEDA (debugging)
kubectl logs -n keda -l app=keda-operator
# Désactiver temporairement un ScaledObject (sans le supprimer)
kubectl annotate scaledobject rabbitmq-consumer-scaler autoscaling.keda.sh/paused=true -n myapp
# Réactiver
kubectl annotate scaledobject rabbitmq-consumer-scaler autoscaling.keda.sh/paused- -n myappListe des scalers populaires
| Scaler | Source de métrique | Cas d'usage |
|---|---|---|
| rabbitmq | Profondeur queue RabbitMQ | Traitement messages asynchrones |
| kafka | Consumer lag Kafka | Streaming events, CDC |
| azure-queue | Azure Queue Storage | Batch processing sur Azure |
| aws-sqs | AWS SQS queue depth | Batch processing sur AWS |
| prometheus | Métriques Prometheus | Application métrique custom |
| postgresql | Nombre de lignes query SQL | Traitement base de données |
| redis | Length de liste Redis | Queues Redis |
| cron | Calendrier | Scaling préventif |
| cpu | CPU usage (comme HPA) | Fallback simple |
| memory | Memory usage | Fallback simple |
Consultez la liste complète des scalers dans la documentation officielle KEDA.
Bonnes pratiques KEDA
Scale-to-zero
Le scale-to-zero est adapté pour :
- Workers de traitement asynchrone (queues, batch)
- Applications pouvant tolérer un cold start (démarrage de Pod)
- Environnements non-production (dev, staging)
Sécurité des credentials
Toujours utiliser TriggerAuthentication + Secret pour les credentials :
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: aws-sqs-auth
namespace: myapp
spec:
secretTargetRef:
- parameter: awsAccessKeyID
name: aws-credentials
key: AWS_ACCESS_KEY_ID
- parameter: awsSecretAccessKey
name: aws-credentials
key: AWS_SECRET_ACCESS_KEYMonitoring KEDA
Intégrez KEDA avec votre stack de monitoring :
# Prometheus ServiceMonitor pour KEDA (préinstallé sur cluster SdV)
kubectl apply -f https://raw.githubusercontent.com/kedacore/keda/main/config/prometheus/monitor.yaml
# Métriques exposées par KEDA
# - keda_scaler_errors_total
# - keda_scaler_metrics_value
# - keda_scaled_object_pausedPerformance et limites
| Paramètre | Valeur par défaut | Recommandation |
|---|---|---|
pollingInterval | 30s | 10-30s pour charges stables, 5-10s pour charges variables |
cooldownPeriod | 300s (5min) | 300-600s pour éviter le flapping |
maxReplicaCount | - | Définir une limite pour éviter l'explosion de coûts |
Comparaison : Quand utiliser HPA ou KEDA ?
Utilisez HPA standard si :
- Vous scalez sur CPU/Memory uniquement
- Vous avez déjà un Prometheus Adapter configuré
- Vous ne nécessitez pas de scale-to-zero
- Architecture simple (API REST, applications stateless classiques)
Utilisez KEDA si :
- Vous avec des workers consommant des queues (RabbitMQ, Kafka, SQS, etc.)
- Le scale-to-zero est nécessaire (économies, environnements éphémères)
- Vous utilisez des sources externes (bases, cloud services)
- Vous voulez combiner plusieurs métriques (cron + prometheus + queue)
- Vous préférez une configuration unifiée (pas d'adapter à maintenir)
Utilisez les deux (hybride) si :
- HPA pour les services web/API (CPU/Memory)
- KEDA pour les workers/batch asynchrones (queues)
Troubleshooting
HPA n'obtient pas les métriques
# Vérifier l'état de l'API custom metrics
kubectl get apiservices v1beta1.custom.metrics.k8s.io
# Vérifier les logs de Prometheus Adapter (adapter le namespace selon votre cluster)
kubectl logs -n <namespace-prometheus> -l app.kubernetes.io/name=prometheus-adapter
# Tester manuellement l'API
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .- Prometheus Adapter mal configuré (mauvaise règle
seriesQuery) - Prometheus ne scrape pas les Pods (annotations manquantes)
- Métrique Prometheus inexistante ou mal nommée
KEDA ne scale pas
# Vérifier l'état du ScaledObject
kubectl get scaledobject -n myapp
kubectl describe scaledobject <name> -n myapp
# Consulter les logs KEDA
kubectl logs -n keda -l app=keda-operator --tail=100
# Vérifier le HPA créé par KEDA
kubectl get hpa -n myapp
kubectl describe hpa <keda-hpa-name> -n myapp- Credentials incorrects (vérifier
TriggerAuthentication) - Connectivité réseau vers la source externe (RabbitMQ, AWS, etc.)
- Requête métrique invalide (PromQL mal formé, queue inexistante)
- MinReplicaCount = MaxReplicaCount (scaling désactivé)
Flapping (oscillations)
Symptômes : Le nombre de Pods oscille rapidement entre 2 valeurs.
- Augmenter
stabilizationWindowSecondsdans HPA - Augmenter
cooldownPerioddans KEDA - Lisser les métriques (moyenne sur fenêtre glissante)
- Ajuster les seuils pour avoir une zone tampon
Ressources et documentation
- Documentation officielle HPA Kubernetes
- Prometheus Adapter GitHub
- Documentation KEDA
- Liste complète des KEDA scalers
- Blog : HPA deep dive
Conclusion
L'autoscaling horizontal est essentiel pour garantir la disponibilité et l'efficacité des applications Kubernetes. Le HPA natif couvre les besoins standards (CPU, Memory, métriques custom via adaptateurs), tandis que KEDA apporte des fonctionnalités avancées pour l'autoscaling événementiel et le scale-to-zero.
Sur un cluster SdV :
- Deployez HPA + Prometheus Adapter pour vos API / applications web classiques
- Ajoutez KEDA pour vos workers asynchrones et traitements batch
- Combinez les deux approches selon vos cas d'usage
L'investissement initial dans l'infrastructure de métriques et d'autoscaling est rapidement rentabilisé par l'amélioration de la disponibilité et l'optimisation des coûts d'exploitation.